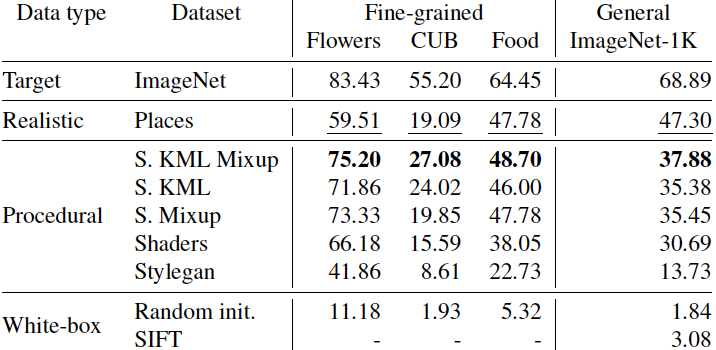
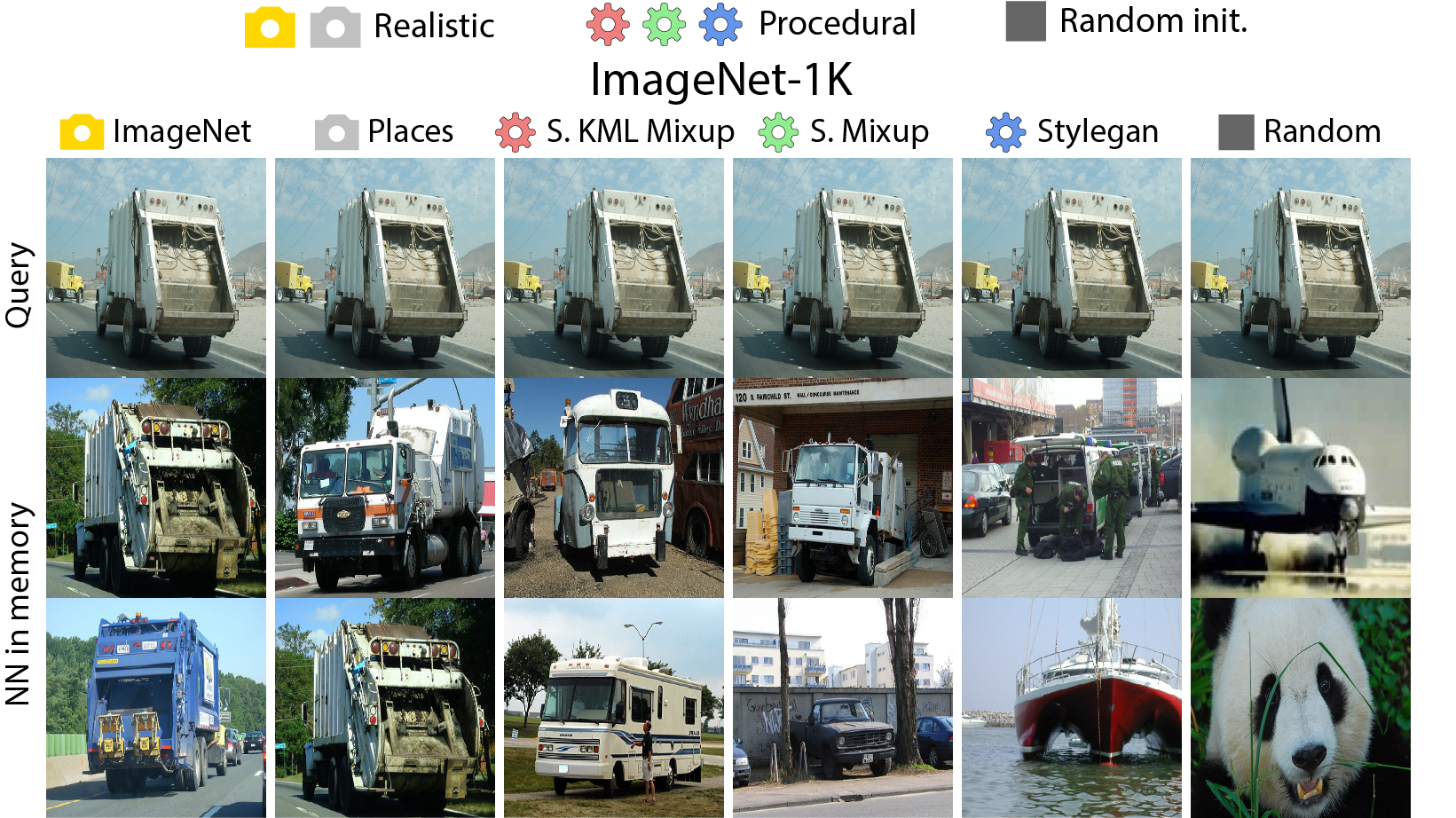
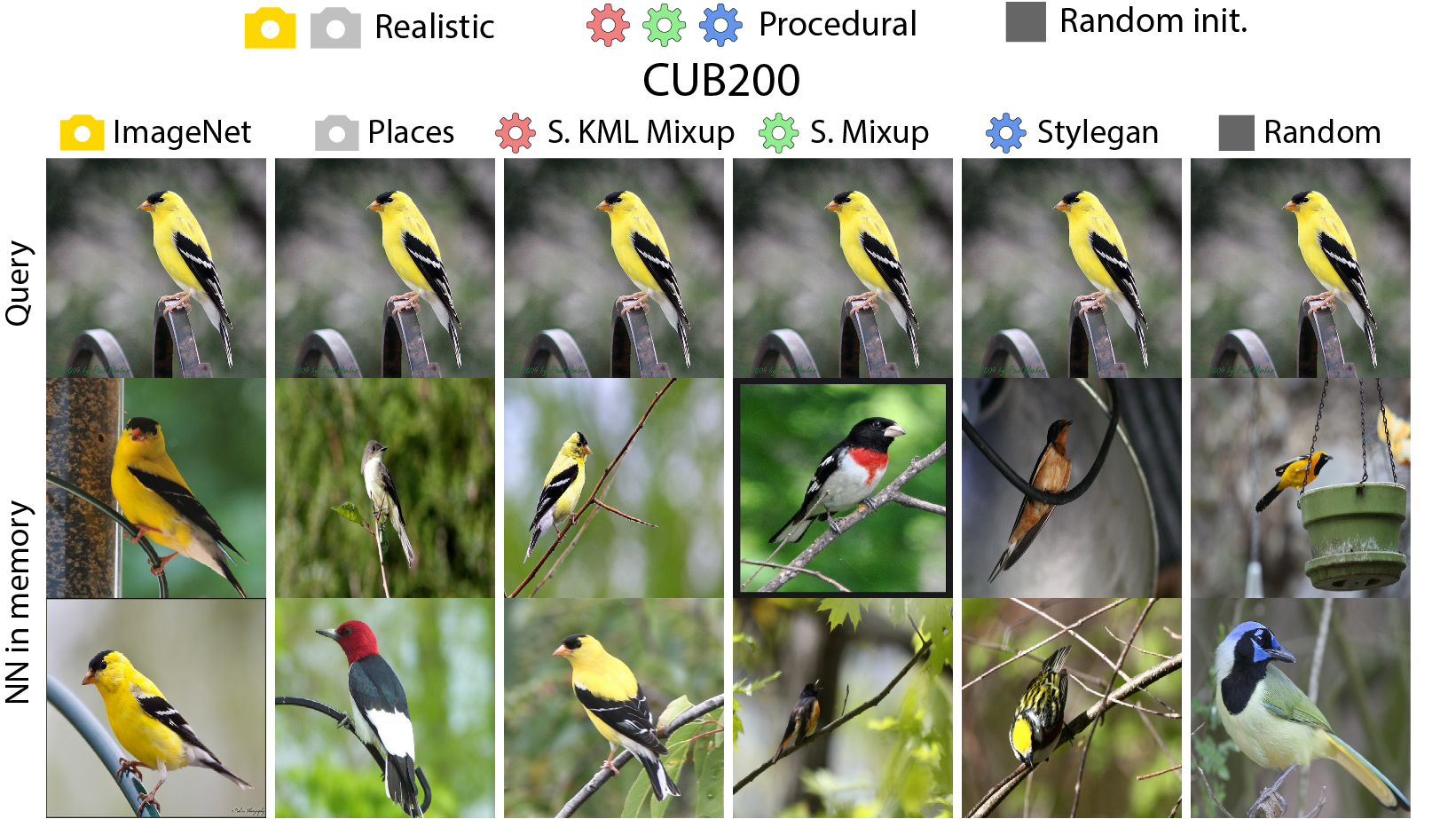
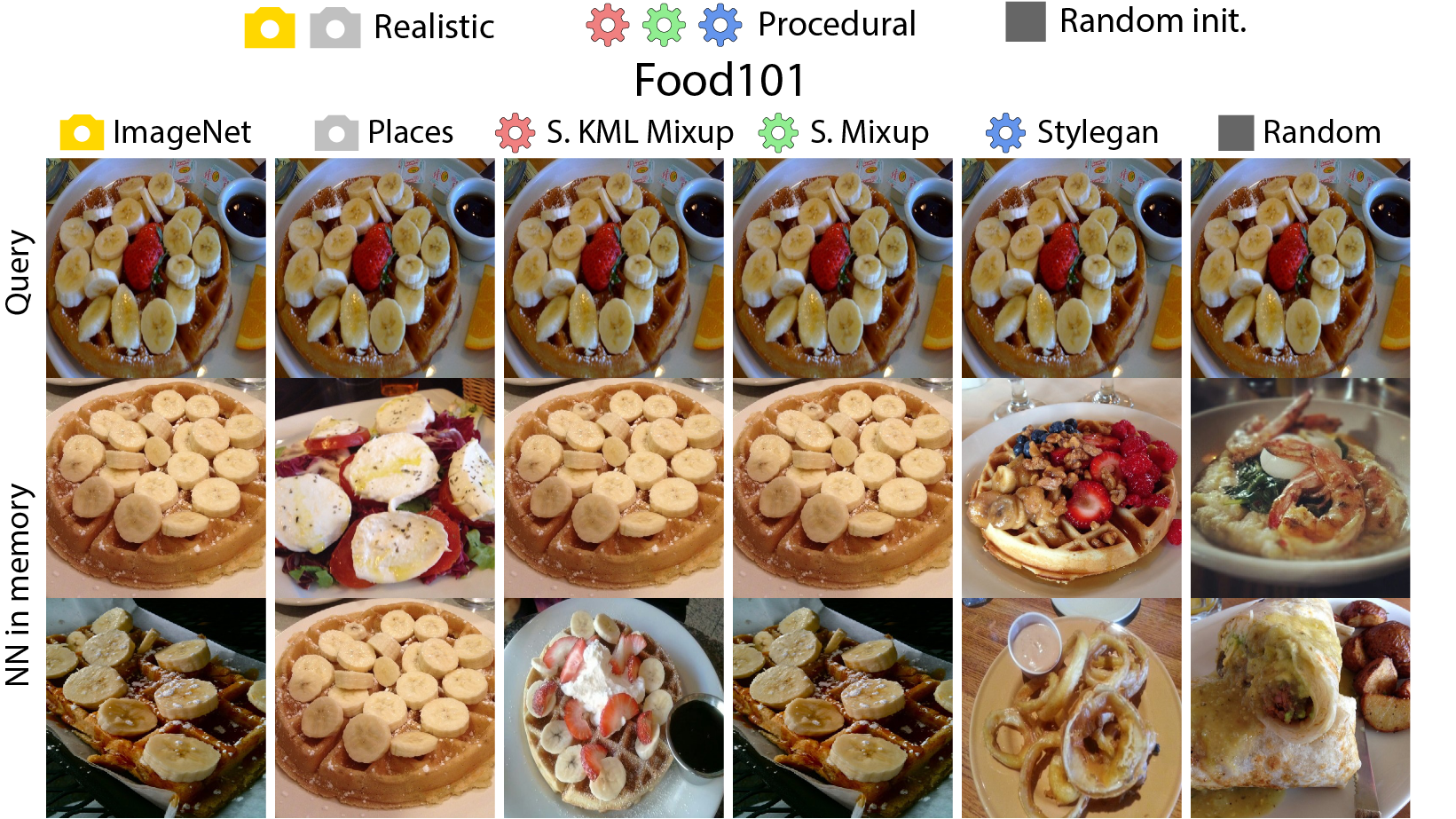
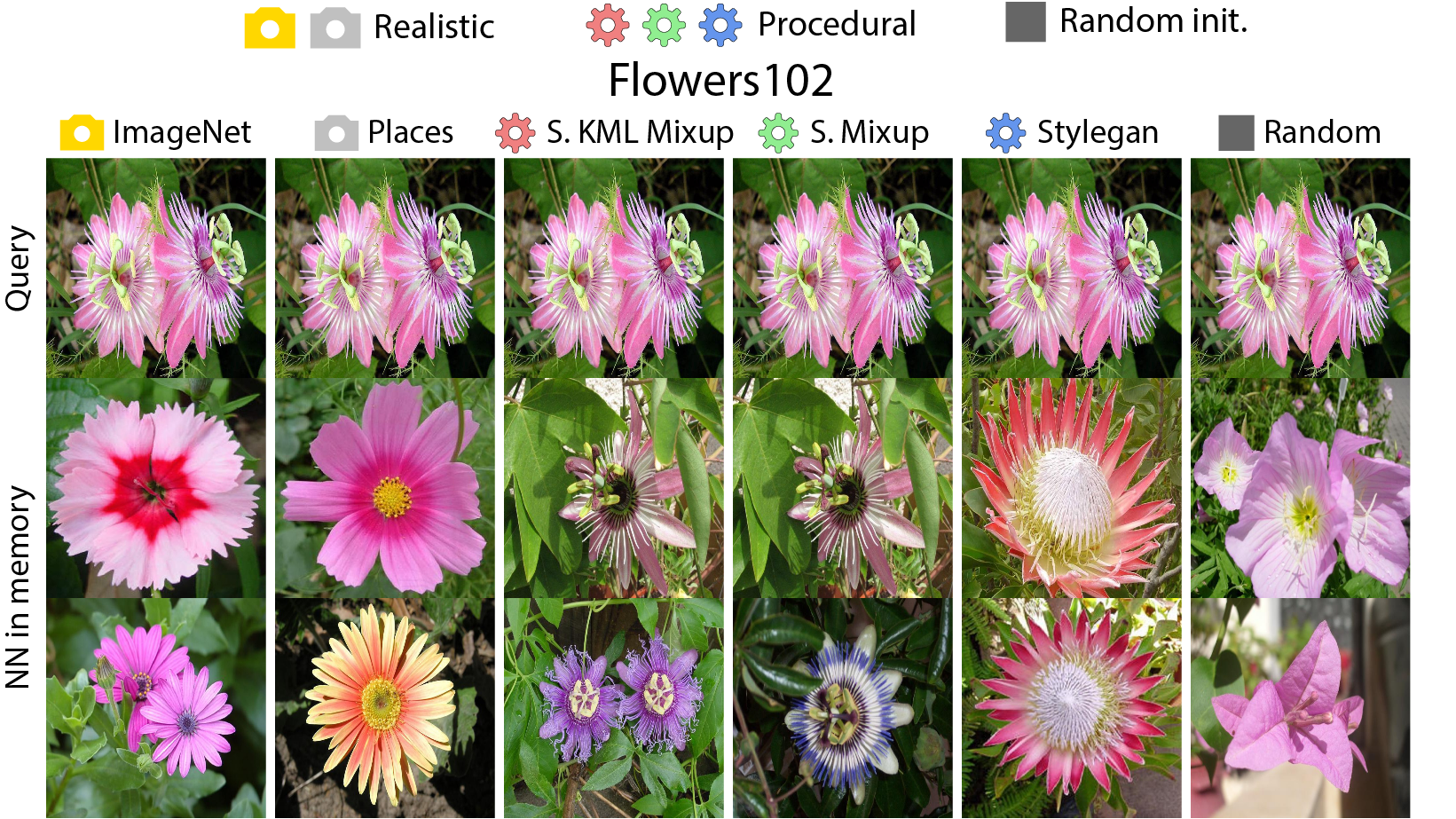
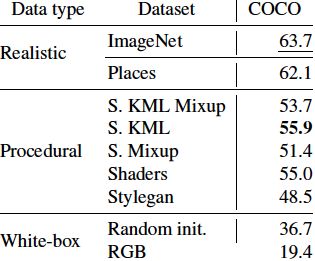
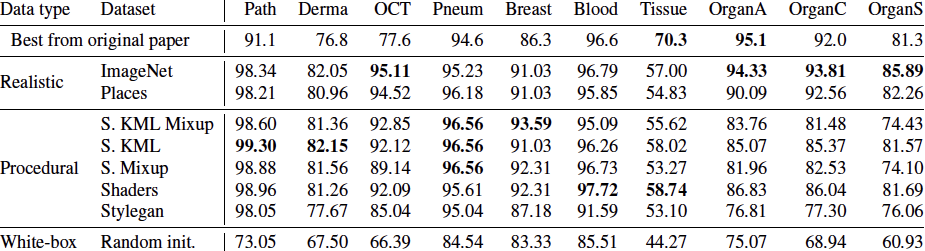
Our approach is as follows: first, an embedding model is trained on procedural data generated with OpenGL code using self-supervised learning (SSL). In this stage, unlearning and attribution is difficult, but procedural data is much less exposed to privacy/bias risk and real-world semantics. Next, we use the embedding model on real world tasks using only a visual memory of reference image embeddings, without extra training. When working with real instead of procedural data, there is high privacy/bias risk and real world semantics. However, isolating all real data to only the memory makes efficient data unlearning and privacy analysis possible. The overall system has perfect control over all real world data, while approximating the performance of standard training.